A year after the publication of PROV recommendations by the W3C provenance working group, it is nice to see the deployment of applications making use of PROV. In this blog, I talk about the 2014 National Climate Assessment report.
A quick reminder of what I mean by provenance:
Provenance is a record that describes the people, institutions, entities, and activities involved in producing, influencing, or delivering a piece of data or a thing.
The W3C PROV recommendations offer a conceptual model for provenance, its mapping to various technologies such as RDF, XML, or simple textual form, but also the means to expose, find and share provenance over the Web.
The National Climate Assessment is a four yearly report published by the US government on climate. “The report of the National Climate Assessment provides an in-depth look at climate change impacts on the U.S. It details the multitude of ways climate change is already affecting and will increasingly affect the lives of Americans.” Given the controversy around climate change, it is a critical piece of evidence-based scientific analysis about climate change.
For the 2014 edition, it was decided that provenance would be used to link all artefacts presented in the report to original data sets, methods and scientific articles. Specifically PROV provenance! According to the authors, “the entity-activity-agent model of PROV has been applied through the use of resources, activities, and contributors”. Let us find some illustrations of PROV and how it is exposed to users, in textual form, but also in machine processable format. For example, dereferencing http://data.globalchange.gov/image/1a061197-95cf-47bd-9db4-f661c711a174, we obtain the following page.
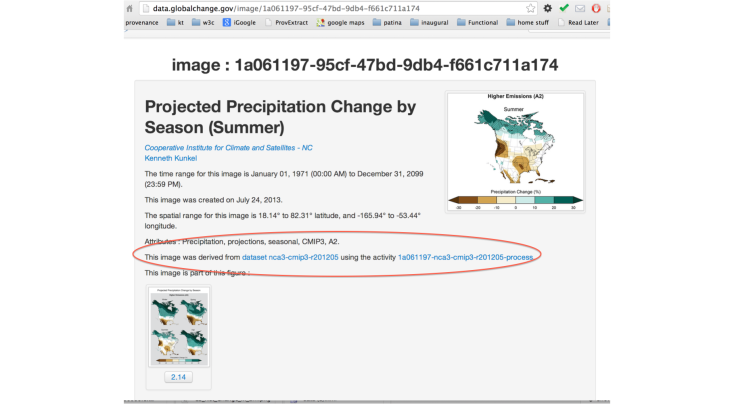
It describes an image resource, which is the projected precipitation change for summer. Besides its attribution to Kenneth Kunkel, we also find interesting provenance information. This image is said to be derived from a specific dataset, and was produced by an activity also linked from that page. This provenance information is not only exposed in textual form, but also it is available in Semantic Web technologies. By clicking on the Turtle button at the bottom of that page, we find a Turtle file including, the following triple including the PROV property prov:wasDerivedFrom.
<http://data.globalchange.gov/image/1a061197-95cf-47bd-9db4-f661c711a174 > prov:wasDerivedFrom <http://data.globalchange.gov/dataset/nca3-cmip3-r201205 > .
Note, I was not able to find properties linking to the activity, nor explicit attribution (though this is also mentioned in the text). So, it seems that not all the information was exposed through this Turtle resource. For details about the underpinning data model, see http://data.globalchange.gov/resources. A REST API is also described at http://data.globalchange.gov/api_reference. All NCA 2014 resources have representations in turtle. Many ontologies are used including, most notably PROV, but also GCIS (An ontology designed for the Global Change Information System) which specializes PROV. A SPARQL Endpoint also exists at http://data.globalchange.gov/sparql.
Overall, NCA 2014 is a very impressive and rich resource, which is not only pleasant to browse, but also exposes very detailed metadata, in particular about the origins of all its artifacts. Congratulations to the NCA team for producing such a system. For the provenance standpoint, it also brings up interesting issues.
- NCA 2014 was a massive exercise in provenance reconstruction. In an ideal world, provenance should not be reconstructed, but directly copied, validated, reproduced, and suitably exposed. There are technological, methodological, and cultural impediments to such reproducibility. That may well be the topic of another blog.
- It is an interesting question as to how provenance should be exposed to end users. The NCA team opted for a simple conversion of PROV to text. It remains an open question as to whether this is the most usable way of making provenance accessible.